为了使用AIACC-Training(AIACC训练加速)进行加速训练,您需要对模型代码做少量修改。本文介绍各框架模型代码和AIACC Training的适配流程。
前提条件
背景信息
AIACC-Training(AIACC训练加速)应用于同步通信场景,训练方式支持数据并行和模型并行,以数据并行为主。如需实现模型并行,要求模型代码可以通过AIACC-Training(AIACC训练加速)提供的通信接口适配,已有支持案例包括InsightFace模型并行、Megatron-LM自动模型并行+数据并行等。
为降低上手难度,AIACC-Training(AIACC训练加速)兼容了主流API,针对TensorFlow、PyTorch兼容Horovod API,针对MXNet同时兼容Horovod API和KVStore API。
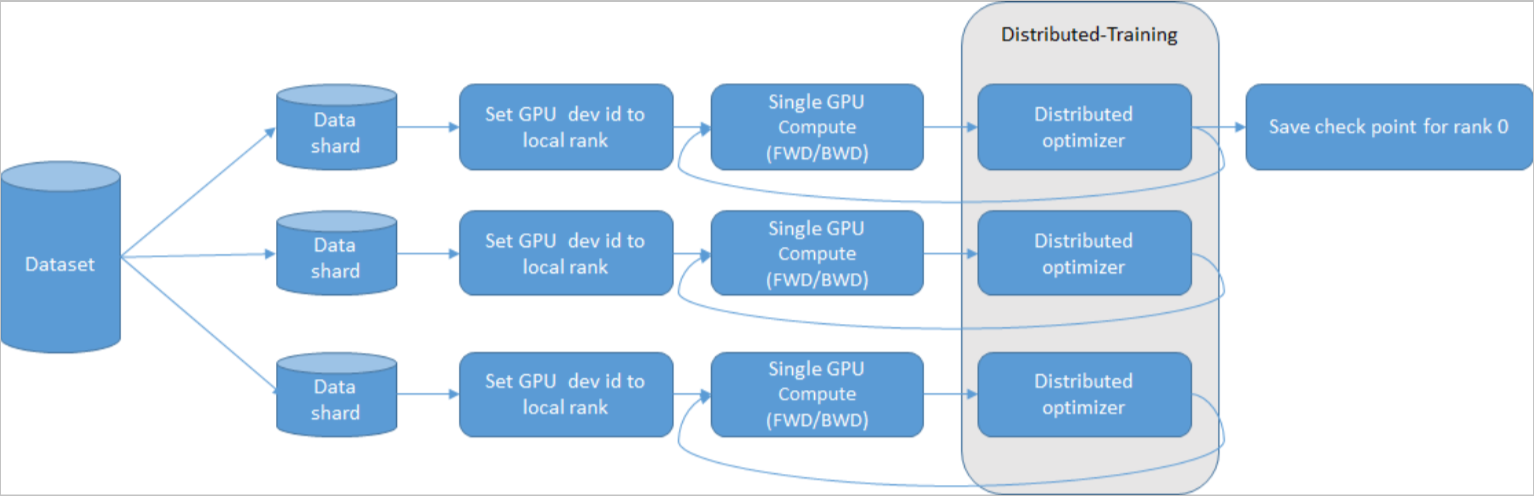
- 划分数据。
- 根据local rank设定对应GPU卡的设备ID。
- 在单GPU卡上运行计算代码,完成前向、后向计算。
- 在更新梯度之前,AIACC-Training(AIACC训练加速)介入进行梯度的集合通信。
TensorFlow模型代码和AIACC-Training(AIACC训练加速)适配
- 导入Perseus Horovod模块。
示例代码:
import perseus.tensorflow.horovod as hvd - 初始化Perseus Horovod模块。
说明 必须在使用其他任何API之前(即main函数的开头部分)完成初始化。示例代码:
hvd.init() - 通常情况下需要根据总worker个数增大学习率,将当前学习率乘以
hvd.size()即可。例如双节点,每节点配备8张GPU卡,则总worker的个数为16。说明 部分模型不需要增大,例如BERT模型。示例代码:# Horovod: scale learning rate by the number of workers. optimizer = tf.train.MomentumOptimizer( learning_rate=0.001 * hvd.size(), momentum=0.9) - 使用
hvd.DistributedOptimizer()重载optimizer。该方法输入参数为标准TensorFlow下的optimizer,输出参数为使用Perseus Horovod重载过的optimizer。示例代码:# Horovod: add Horovod Distributed Optimizer. optimizer = hvd.DistributedOptimizer(optimizer) - 在session hook中加入
BroadcastGlobalVariablesHook(0),用于在训练开始时将全局变量参数广播到所有节点。在调用train之前定义广播用hook,在调用train时加入该hook,同时step数需要除以总worker的个数(即size())。示例代码:# Horovod: BroadcastGlobalVariablesHook broadcasts initial variable states from # rank 0 to all other processes. This is necessary to ensure consistent # initialization of all workers when training is started with random weights or # restored from a checkpoint. bcast_hook = hvd.BroadcastGlobalVariablesHook(0) # Horovod: adjust number of steps based on number of GPUs. mnist_classifier.train( input_fn=train_input_fn, steps=20000 // hvd.size(), hooks=[logging_hook, bcast_hook]) - 将当前进程绑定对应的GPU卡。
使用
local_rank()获取GPU卡在节点上的编号。例如配备8张卡的节点,调用local_rank()会返回0-7,您可以根据编号将进程绑定到对应的GPU卡。示例代码:config = tf.ConfigProto() config.gpu_options.allow_growth = True config.gpu_options.visible_device_list = str(hvd.local_rank()) - 在root rank上保存checkpoint,其它设置为None,保证各个worker不会相互覆盖引起冲突。
示例代码:
checkpoint_dir = './checkpoints' if hvd.rank() == 0 else None
PyTorch模型代码和AIACC-Training(AIACC训练加速)适配
- 导入Perseus Horovod模块。
示例代码:
import horovod.torch as hvd - 初始化Perseus Horovod模块。
说明 必须在使用其他任何API之前(即main函数的开头部分)完成初始化。示例代码:
hvd.init() - 将当前进程绑定对应的GPU卡。
示例代码:
torch.cuda.set_device(hvd.local_rank()) - 通常情况下需要根据总worker个数增大学习率,将当前学习率乘以
hvd.size()即可。例如双节点,每节点配备8张卡,则总worker的个数为16。说明 部分模型不需要增大,例如BERT模型。 - 重载optimizer。
示例代码:
optimizer = hvd.DistributedOptimizer( optimizer, named_parameters=model.named_parameters())涉及多个模型时会有多个named_parameters,需要合并named_parameters。示例代码:all_named_parameters = [] for name, value in model1.named_parameters(): all_named_parameters.append((name, value)) for name, value in model2.named_parameters(): all_named_parameters.append((name, value)) optimizer = hvd.DistributedOptimizer( optimizer, named_parameters=all_named_parameters) - 将全局变量参数广播到所有节点。
示例代码:
hvd.broadcast_parameters(model.state_dict(), root_rank=0) hvd.broadcast_optimizer_state(optimizer, root_rank=0)涉及多个模型时会有多个state_dict,需要合并state_dict。示例代码:all_state_dict={} all_state_dict.update(model1.state_dict()) all_state_dict.update(model2.state_dict()) hvd.broadcast_parameters(all_state_dict, root_rank=0) - 划分数据。
示例代码:
train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=hvd.size(), rank=hvd.rank()) loader = torch.utils.DataLoader( train_dataset, batch_size=batch_size, sampler=train_sampler, **kwargs) - 将程序设置为单机单卡运行方式。
Perseus Horovod用于运行单机单卡程序,然后将任务下发给各GPU卡进行分布式训练,实现单机多卡的效果。
示例原始代码:model = nn.DataParallel(model.cuda())示例修改后代码:# 方式1 model = nn.DataParallel(model.cuda(), device_ids=[hvd.local_rank()]) # 方式2,前方步骤3中进程已绑定至GPU卡,cuda()方法会默认寻找当前进程绑定的GPU卡 model = model.cuda() - 保存checkpoint。
只需要在进程0上保存checkpoint、verbose、tensorboardX信息,防止其他进程冲突。
save_checkpoint = True if hvd.rank() == 0 else False verbose = 1 if hvd.rank() == 0 else 0 log_writer = tensorboardX.SummaryWritter(log_dir) if hvd.rank() == 0 else None - 加载checkpoint。
if hvd.rank() == 0: checkpoint = torch.load(filepath) model.load_state_dict(checkpoint[‘model’]) optimizer.load_state_dict(checkpoint[‘optimizer’])
- 单机8卡(共8个进程)
mpirun –allow-run-as-root -np 8 -npernode 8 -x NCCL_DEBUG=INFO ./train.sh - 4机8卡(共32个进程)
mpirun –allow-run-as-root –bind-to none -np 32 -npernode 8 \ -x NCCL_DEBUG=INFO -x PATH -x LD_LIBRARY \ -x PERSEUS_ALLREDUCE_STREAMS=8 -hostfile mpi_host.txt ./train.sh
MXNet模型代码和AIACC-Training(AIACC训练加速)适配
针对MXNet,AIACC-Training(AIACC训练加速)兼容Horovod API和KVStore API。
- 导入Perseus Horovod模块。
示例代码:
import perseus.mxnet as hvd - 初始化Perseus Horovod模块。
示例代码:
hvd.init() - 将当前进程绑定对应的GPU卡。通常情况下需要根据总worker个数增大学习率,将当前学习率乘以
hvd.size()即可。说明 部分模型不需要增大,例如BERT模型。示例代码:# rank and size rank = hvd.rank() num_workers = hvd.size() local_rank = hvd.local_rank() # Horovod: pin GPU to local rank context = mx.gpu(local_rank) - 重载optimizer。
示例代码:
opt = mx.optimizer.create(optimizer, **optimizer_params) # Horovod: create DistributedTrainer, a subclass of gluon.Trainer trainer = hvd.DistributedTrainer(params, opt) - 将全局变量参数广播到所有节点。
示例代码:
# Horovod: fetch and broadcast parameters params = net.collect_params() if params is not None: hvd.broadcast_parameters(params)
ctx设置。下方示例代码将当前进程绑定至kv.local_rank对应的GPU卡: ctx = []
cvd = os.environ['DEVICES'].strip()
if 'perseus' in args.kv_store:
import perseus.mxnet as perseus
ctx.append(mx.gpu(kv.local_rank))- 修改模型代码,主要修改点为Perseus MXNet模块导入、KVStore的创建方法。
示例原始代码:
diff --git a/example/image-classification/common/fit.py b/example/image-classification/common/fit.py index 9412b6f..3a6e9a0 100755 a/example/image-classification/common/fit.py @@ -22,6 +22,7 @@ import time import re import math import mxnet as mx def _get_lr_scheduler(args, kv): @@ -146,7 +147,8 @@ def fit(args, network, data_loader, **kwargs): data_loader : function that returns the train and val data iterators """ # kvstore kv = mx.kvstore.create(args.kv_store)示例修改后代码:diff --git a/example/image-classification/common/fit.py b/example/image-classification/common/fit.py index 9412b6f..3a6e9a0 100755 b/example/image-classification/common/fit.py @@ -22,6 +22,7 @@ import time import re import math import mxnet as mx import perseus.mxnet as perseus_kv def _get_lr_scheduler(args, kv): @@ -146,7 +147,8 @@ def fit(args, network, data_loader, **kwargs): data_loader : function that returns the train and val data iterators """ # kvstore kv = perseus_kv.create(args.kv_store) if args.kv_store == dist_sync_perseus else mx.kvstore.create(args.kv_store) if args.gc_type != 'none': kv.set_gradient_compression({'type': args.gc_type, 'threshold': args.gc_threshold}) - 准备执行训练任务所需的配置脚本config.sh。
通过配置脚本保证在执行训练任务时将进程绑定至对应的GPU卡,重点是设定MPI环境变量MXNET_VISIBLE_DEVICE,该环境变量用于获取进程对应的GPU设备ID,并将GPU设备ID作为参数传递到模型代码中用于创建对应的ctx。
config.sh示例如下:
#!/bin/sh let GPU=OMPI_COMM_WORLD_RANK % OMPI_COMM_WORLD_LOCAL_SIZE export OMP_NUM_THREADS=4 MXNET_VISIBLE_DEVICE=$GPU python train_imagenet.py \ --network resnet \ --num-layers 50 \ --kv-store dist_sync_perseus \ --gpus $GPU … - 执行训练任务。
由于使用AIACC-Training(AIACC训练加速)时不存在参数服务器,因此通过mpirun命令执行训练任务。在4机8卡(共32个进程)上执行训练任务的示例命令如下:
mpirun –np 32 –npernode 8 –hostfile mpi_host.txt ./config.sh其中,mpi_host.txt用于指定节点的IP地址,是一个普通的MPI machine file,和原生MXNet使用ssh launcher时的host file类似。mpi_host.txt内容示例如下:192.168.0.1 192.168.0.2 192.168.0.3 192.168.0.4开源版本MXNet默认占用系统所有的CPU资源,因此在训练任务启动阶段会占用较多的CPU时间,导致启动速度较慢。您可以尝试配置以下环境变量提升启动速度:export MXNET_USE_OPERATOR_TUNING=0; export MXNET_USE_NUM_CORES_OPERATOR_TUNING=1 export OMP_NUM_THREADS=1 - 开始训练后,每张GPU卡各自占用一个进程并输出训练结果。
针对物体识别等Batch Size较小的场景,在每张GPU卡上进行BatchNorm计算得到的均值和方差存在较大的偏差,会带来一定的精度损失。SyncBatchNorm相比原始BatchNorm能够牺牲一定训练性能,提高收敛精度的上限。
- 安装补丁。
patch -p1 < perseus-mxnet-sync-bn.patch - 编译源码。
make USE_OPENCV=1 USE_BLAS=openblas USE_CUDA=1 USE_CUDA_PATH=/usr/local/cuda USE_CUDNN=1 USE_DIST_KVSTORE=1 USE_NCCL=1 USE_LIBJPEG_TURBO=1 MPI_ROOT=/usr/local -j24SyncBatchNorm基于MXNet官方代码src/operator/contrib/sync_batch_norm-inl.h实现,通过加载libperseus_mxnet.so调用Perseus MXNet的通信API,在算子内部实现跨卡同步BN。
- 调用跨卡同步BN的方法。
SyncBatchNorm基于MXNet官方代码,因此兼容原始的使用方法,将名称变为PerseusSyncBatchNorm并视需要修改同步模式即可。例如,mx.gluon.contrib.nn.PerseusSyncBatchNorm(comm_scope=0)、mx.sym.contrib.PerseusSyncBatchNorm(comm_scope=0)。
支持单机local模式以及全局global模式。- 单机模式:默认为该模式,局部平均(comm_scope=0),即每次前向、后向时计算均值和方差后,只在单机内部同步各GPU卡之间的结果。
- 全局模式:全局平均(comm_scope=1),即每次前向、后向时计算均值和方差后,在全部节点之间同步各GPU卡之间的结果。
Caffe模型代码和AIACC-Training(AIACC训练加速)适配
- 为BVLC Caffe安装补丁。
- 确认BVLC Caffe的版本为
99bd99795dcdf0b1d3086a8d67ab1782a8a08383 - 安装补丁。
git apply perseus-dist-1.2.0/patches/bvlc_caffe/1_perseus_distribute_train.patch git apply perseus-dist-1.2.0/patches/bvlc_caffe/2_cudnn_batchnorm.patch git apply perseus-dist-1.2.0/patches/bvlc_caffe/3_data_augmentation.patch其中,1_perseus_distribute_train.patch用于支持AIACC-Training(AIACC训练加速)分布式训练功能,2_cudnn_batchnorm.patch用于支持cuDNN Batch Norm功能,3_data_augmentation.patch用于支持ImageData Layer的数据增强功能。如果只需要分布式训练功能,只需要安装1_perseus_distribute_train.patch。
- 确认BVLC Caffe的版本为
- 运行命令重新编译Caffe。
二进制文件的输出目录位于$HOME/perseus-caffe-dist。
cd $HOME/caffe/build cmake -DCMAKE_INSTALL_PREFIX=$HOME/perseus-caffe-dist -DBLAS=open -DUSE_PERSEUS=ON -DPERSEUS_LIBRARY_PATH=/root/caffe/libperseus-caffe.so .. make all -j16 && make instal - 执行分布式训练任务。
2机8卡(共16个进程)示例命令:
mpirun --allow-run-as-root -np 16 -npernode 8 \ -machinefile /root/hostfile \ --mca bind-to none \ --mca btl_tcp_if_include eth0 \ --mca orte_keep_fqdn_hostnames t \ -x NCCL_IB_DISABLE=1 \ -x NCCL_SOCKET_IFNAME=eth0 \ -x LD_LIBRARY_PATH \ -x NCCL_DEBUG=INFO \ /root/perseus-caffe-dist/bin/caffe train --solver solver.prototxt说明caffe train命令中无需指定GPU ID,AIACC-Training(AIACC训练加速)会根据启动的进程数量自动分配GPU资源。








