为了使用AIACC-Inference(AIACC推理加速) TensorFlow版加速推理,您需要调用AIACC-Inference(AIACC推理加速) TensorFlow版的接口优化模型。本文介绍优化模型和执行推理任务的流程。
前提条件
- 已安装AIACC-Inference(AIACC推理加速) TensorFlow版。具体操作,请参见自动安装AIACC-Inference(AIACC推理加速)和手动安装AIACC-Inference(AIACC推理加速) TensorFlow版。
- GPU实例上已准备待优化的模型。
背景信息
AIACC-Inference(AIACC推理加速) TensorFlow版支持优化基于TensorFlow搭建的图像分类和检测模型,优化方法是分析模型中包含的计算图,对计算图中包含的计算节点执行融合操作,从而减少模型中计算节点的个数,提升计算图的执行效率。AIACC-Inference(AIACC推理加速)
TensorFlow版支持优化的模型包括但不限于:
- ResNet
- Inception V4
- SSD
- Faster-RCNN
- Mask-RCNN
- Yolo V3
AIACC-Inference(AIACC推理加速) TensorFlow版提供了FP32和FP16两种精度的模型优化选项,用于生成不同精度的优化模型。NVIDIA Volta和Turing架构下的Tensor Core硬件,进一步提升在V100、T4 GPU上的推理性能。
操作步骤
- 基于优化后模型执行推理任务。在代码中增加导入AIACC-Inference(AIACC推理加速) TensorFlow版的库即可,无需在其他位置调整代码。
import aiacc_inference_tf说明 不支持跨硬件类型使用模型。例如,在V100 GPU上优化的模型不能用于在T4 GPU上执行推理任务。
Frozen Graph格式输入Frozen Graph格式输出
优化接口定义:
optimize_tf_model(model_fname, output_names, output_model, batch_size, precision)| 参数 | 类型 | 说明 |
|---|---|---|
| graph_file | String | 原始模型的文件名。model_fname对应的形参和格式有关,Frozen Graph格式对应graph_file。 |
| output_names | String List | 原始模型的输出节点名。 |
| output_model | String | 优化后模型的文件名。 |
| batch_size | List | 基于模型执行推理任务时使用的Batch Size。支持指定多个Batch Size,生成模型后您可以使用其中任一个Batch Size。 |
| precision | String | 优化模型时使用的精度。取值范围:
|
优化Inception V4模型示例:
import tensorflow as tf
from aiacc_inference_tf.libaiacc_inference_tf import *
graph_file = './inception_v4.pb'
output_names = ['classes', 'logits']
output_model = './opt_model.pb'
batch_size = [ 1, 2, 4, 8 ]
optimize_tf_model(graph_file, output_names, output_model, batch_size, 'FP16')Frozen Graph格式输入Saved Model格式输出
优化接口定义:
optimize_tf_model_v2(model_fname, saved_model_dir,
input_names, output_names,
input_tensor_names, output_tensor_names,
signature_key,
batch_size, precision)| 参数 | 类型 | 说明 |
|---|---|---|
| graph_pb | String | 原始模型的文件名。model_fname对应的形参和格式有关,Frozen Graph格式对应graph_pb。 |
| export_dir | String | 优化后模型所在Saved Model目录的名称。saved_model_dir对应的形参和格式有关,Saved Model格式对应export_dir。 |
| input_names | String List | Saved Model使用的SignatureDef中指定输入节点的名称。 |
| output_names | String List | Saved Model使用的SignatureDef中指定输出节点的名称。 |
| input_tensor_names | String List | 原始模型的输入节点名。 |
| output_tensor_names | String List | 原始模型的输出节点名。 |
| signature_key | String | Saved Model使用的SignatureDef的签名键。
如果为该参数取值为None,则默认使用 |
| batch_size | List | 基于模型执行推理任务时使用的Batch Size。支持指定多个Batch Size,生成模型后您可以使用其中任一个Batch Size。 |
| precision | String | 优化模型时使用的精度。取值范围:
|
优化Yolo V3模型示例:
import tensorflow as tf
from aiacc_inference_tf.libaiacc_inference_tf import *
export_dir = './saved_model/1'
graph_pb = './yolo.pb'
input_names = [ 'input', 'placeholder' ]
output_names = [ 'out_boxes', 'out_scores', 'out_classes' ]
input_tensor_names = ['input_1', 'Placeholder_366']
output_tensor_names = ['concat_11', 'concat_12', 'concat_13']
signature_key = 'predict'
batch_size = [ 1 ]
optimize_tf_model_v2(graph_pb, export_dir, input_names, output_names,
input_tensor_names, output_tensor_names, signature_key, batch_size, 'FP16')您可以使用saved_model_cli查看Saved Model模型的信息,查看SignatureDef输入输出信息的示例,如下图所示。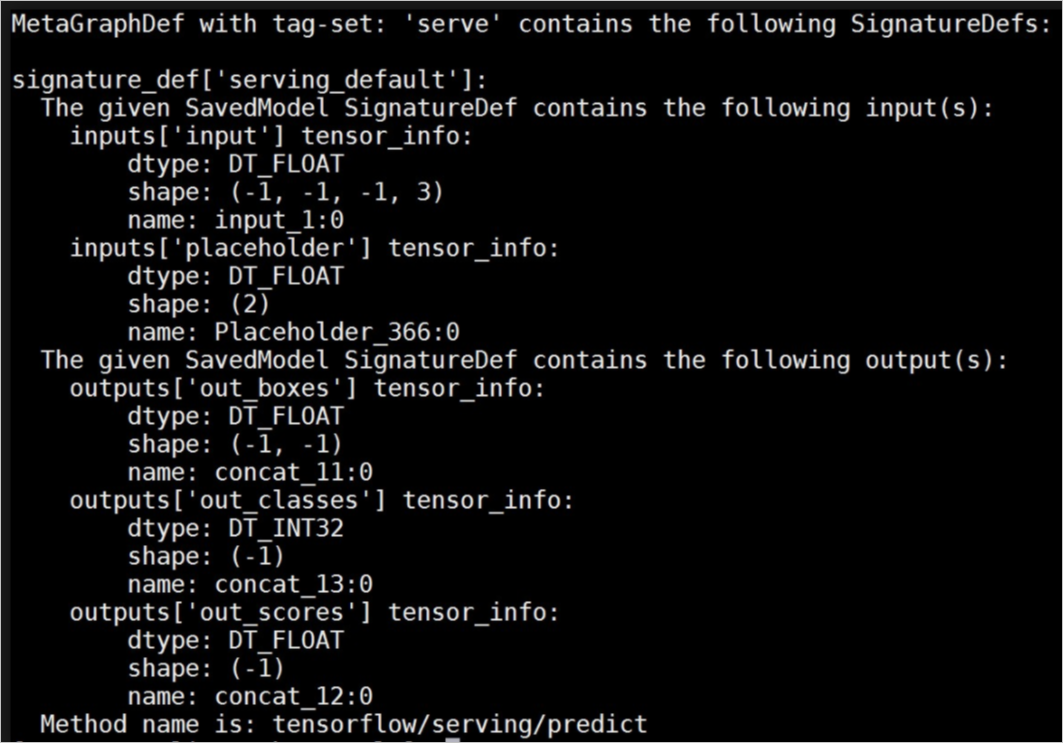
Saved Model格式输入Saved Model格式输出
优化接口定义:
optimize_tf_saved_model(input_model_dir, saved_model_dir, signature_key, batch_size, precision)| 参数 | 类型 | 说明 |
|---|---|---|
| input_dir | String | 原始模型所在Saved Model目录的名称。input_model_dir对应的形参和格式有关,Saved Model格式对应input_dir。 |
| export_dir | String | 优化后模型所在Saved Model目录的名称。saved_model_dir对应的形参和格式有关,Saved Model格式对应export_dir。 |
| signature_key | String | Saved Model使用的SignatureDef的签名键。
如果为该参数取值为None,则默认使用 |
| batch_size | List | 基于模型执行推理任务时使用的Batch Size。支持指定多个Batch Size,生成模型后您可以使用其中任一个Batch Size。 |
| precision | String | 优化模型时使用的精度。取值范围:
|
优化ResNet模型示例:
import tensorflow as tf
from aiacc_inference_tf.libaiacc_inference_tf import *
input_dir = './resnet_v2_fp32_savedmodel_NHWC/1538****'
export_dir = './saved_model/1'
signature_key = 'predict'
batch_size = [ 1 ]
optimize_tf_saved_model(input_dir, export_dir, signature_key, batch_size, 'FP16')Keras模型
如果您基于Keras搭建了模型,可以将Keras模型转换为TensorFlow模型,然后使用AIACC-Inference(AIACC推理加速) TensorFlow版优化模型。Keras到TensorFlow模型的转换方法和具体模型的实现有关,您必须先调用通过tensorflow.keras.models.load_model()加载模型。
- 如果可以加载,提供了接口自动将Keras模型转换为TensorFlow模型,并优化模型。
- 如果不能加载,您需要手动将Keras模型转换为TensorFlow模型,然后使用AIACC-Inference(AIACC推理加速) TensorFlow版优化模型。
优化接口定义:
optimize_keras_model(model_fname, output_model, batch_size, precision)| 参数 | 类型 | 说明 |
|---|---|---|
| graph_file | String | 原始模型的文件名。model_fname对应的形参和格式有关,Frozen Graph格式对应graph_file。 |
| output_model | String | 优化后模型的文件名。 |
| batch_size | List | 基于模型执行推理任务时使用的Batch Size。支持指定多个Batch Size,生成模型后您可以使用其中任一个Batch Size。 |
| precision | String | 优化模型时使用的精度。取值范围:
|
优化Keras H5格式模型示例:
import tensorflow as tf
from aiacc_inference_tf.libaiacc_inference_tf import *
graph_file = './model.h5'
output_model = './opt_model.pb'
batch_size = [ 1 ]
optimize_keras_model(graph_file, output_model, batch_size, 'FP16')NPU模型
优化接口定义:
convert_npu_saved_model(model_fname, saved_model_dir,
input_names, output_names,
input_tensor_names, output_tensor_names,
signature_key)说明 该接口用于优化已完成量化的NPU模型,支持Frozen Graph格式输入Saved Model格式输出。
| 参数 | 类型 | 说明 |
|---|---|---|
| graph_file | String | 原始模型的文件名。model_fname对应的形参和格式有关,Frozen Graph格式对应graph_file。 |
| export_dir | String | 优化后模型所在Saved Model目录的名称。saved_model_dir对应的形参和格式有关,Saved Model格式对应export_dir。 |
| input_names | String List | Saved Model使用的SignatureDef中指定输入节点的名称。 |
| output_names | String List | Saved Model使用的SignatureDef中指定输出节点的名称。 |
| input_tensor_names | String List | 原始模型的输入节点名。 |
| output_tensor_names | String List | 原始模型的输出节点名。 |
| signature_key | String | Saved Model使用的SignatureDef的签名键。
如果为该参数取值为None,则默认使用 |
StyleGAN模型
优化接口定义:
convert_graph_to_half(graph_file, output_names, output_model, keep_list = [])说明 该接口用于将StyleGAN模型的精度从FP32转换为FP16,通过压缩模型达到一定的加速效果。
| 参数 | 类型 | 说明 |
|---|---|---|
| graph_file | String | 原始模型的文件名。 |
| output_names | String List | 原始模型的输出节点名。 |
| output_model | String | 优化后模型的文件名。 |
| keep_list | String List | 原始模型中需要保持精度为FP32的节点。 |
优化模型示例:
from aiacc_inference_tf.libaiacc_inference_tf import *
graph_file = 'graph.pb'
output_names = ['Gs/_Run/concat']
output_model = 'opt_graph.pb'
convert_graph_to_half(graph_file, output_names, output_model)







